Houve uma época em que somente grandes empresas falavam de recuperação de desastres. A computação em nuvem mudou isso e, agora, toda empresa pode ter um plano de contingência para seguir operando quando ocorrem incidentes.
E, justamente por isso, o nível de exigência dos clientes aumentou. Situações adversas de qualquer natureza deixaram de ser motivos aceitáveis para perda de dados ou interrupção significativa do fluxo de negócios.
Um plano de BC/DR (continuidade de negócios e recuperação de desastres) deve prever a ocorrência de falhas de infraestrutura, mas também deve contemplar erros operacionais e ameaças virtuais, como ataques de ransomware. E é necessário para qualquer tipo de ambiente, seja na rede interna ou na nuvem.
Mas, afinal, o que é BC/DR?
BC/DR é a capacidade da empresa retomar suas operações de TI completamente após de um incidente grave, como:
- interrupção de energia ou conectividade,
- falhas de hardware ou software,
- erros operacionais,
- ataques cibernéticos,
- desastres naturais.
Qual a diferença entre recuperação de desastres e backup de dados?
Tanto a recuperação de desastres quanto o backup de dados envolvem a realização de cópias de segurança para proteção contra perda, adulteração ou roubo de dados. No entanto, o backup foca na cópia dos dados para mídias alternativas, que podem ser locais (on-site) ou remotas (off-site). Para saber mais, leia o nosso Guia do Backup na Nuvem.
Já a recuperação de desastres, requer que um segundo ambiente, geograficamente distante do ambiente primário, seja preparado para assumir a produção quando o site primário ficar indisponível. O site de DR pode ser implantado fisicamente ou em um provedor de cloud como a Central Server.
O que significam os termos RPO e RTO?
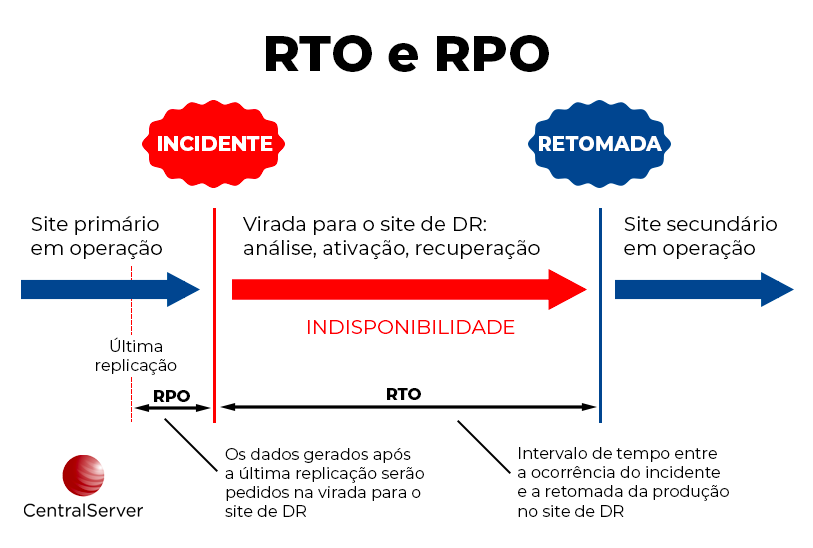
RPO se refere ao Recovery Point Objective, que é o tempo máximo de perda das atualizações de dados durante o processo de recuperação. Um RPO de 1 hora significa que as transações ocorridas durante este período poderão ser perdidas devido a uma interrupção não planejada. Quanto menor o RPO, maior a frequência necessária de replicação dos dados, o que resulta em aumento dos custos.
Já RTO significa Recovery Time Objective, que é o tempo que se leva para recuperar as operações após uma interrupção. Um RTO baixo significa um recuperação mais rápida e, via de regra, a um custo maior.
Como implantar e operar a recuperação de desastres?
Para implantar a recuperação de desastres, a organização precisa:
- Fazer backup dos dados com frequência diária (ou várias vezes ao dia), mantendo cópias locais e remotas.
- Implantar o site secundário com a infraestrutura necessária para rodar as aplicações e serviços em produção.
- Implantar um mecanismo de replicação dos dados do site primário para o secundário.
- Definir rotinas de virada do site primário para o secundário e vice-versa.
- Em caso de desastre, restaurar a cópia mais recente dos dados e executar a virada para dar continuidade às operações de TI.
Como tornar mais eficaz a recuperação de desastres?
Sob o ponto de vista dos investimentos, é possível otimizar o custo do BC/DR usando a nuvem. Isto porque a nuvem permite implantar a infraestrutura do site secundário com menos recursos, mantendo-os em “chama piloto”, para que seja feita a expansão somente quando ocorrer um desastre.
Soluções como AWS Elastic DR, Azure Site Recovery e Veeam Backup & Replication permitem replicar os dados com eficiência, usando compressão e deduplicação, além de automatizar a virada do BC/DR, evitando erros operacionais e acelerando o processo.
E uma questão muito importante: é preciso testar o BC/DR regularmente. Somente assim você terá a confiança de que conseguirá restaurar os sistemas e aplicações frente a um incidente.
Quer aprofundar ainda mais os seus conhecimentos? Leia o nosso Guia Completo sobre a Continuidade de Negócios.
As soluções fornecidas pela CentralServer facilitam a implantação e operação do BC/DR para a sua empresa. Clique aqui e fale com um dos nossos Consultores sobre o seu projeto.